Fully Augmented \(n\)-link Pendulum Benchmark Comparison#
In this notebook we use the \(n\)-link pendulum example to compare the performance of kdFlex’s default SOA-base \(O(N)\) dynamics algorithm with the conventonal \(O(N^{3}\)) methods for a fully augmented (FA) model. This notebook is similar to the \(n\)-link pendulum but is designed for benchmarking kdFlex’s simulation performance.
Requirements:
In this tutorial we will:
Define a method to create the multibody
Run simulations for each model
Benchmark simulation runtimes
For a more in-depth descriptions of kdflex concepts see usage.
import os
import gc
import numpy as np
import time
from typing import cast
import pandas as pd
import plotly.express as px
from Karana.Core import discard, allFinalized
from Karana.Frame import FrameContainer
from Karana.Math import IntegratorType
from Karana.Dynamics import (
Multibody,
PhysicalBody,
PhysicalBody,
HINGE_TYPE,
StatePropagator,
TimedEvent,
PhysicalBodyParams,
)
from Karana.Math import SpatialInertia, HomTran
from Karana.Models import UniformGravity
Define a Method to Create the Multibody#
Define a method that procedurally creates a n-link multibody for use when we run simulations with increasing number of links. This is the same as in the n-link Pendulum
See Multibody or Frames for more information relating to this step.
def createMbody(fc: FrameContainer, n_links: int):
"""Create the multibody.
Parameters
----------
n_links : int
The number of pendulum links to use.
"""
mb = Multibody("mb", fc)
# Here, we use the addSerialChain method to add multiple instances of the same body
# connected in a chain. We add n instances of the pendulum link with the following parameters:
params = PhysicalBodyParams(
SpatialInertia(2.0, np.zeros(3), np.diag([3, 2, 1])),
[np.array([0.0, 1.0, 0.0])],
HomTran(np.array([0, 0, 0.5])),
HomTran(np.array([0, 0, -0.5])),
)
PhysicalBody.addSerialChain(
"link", n_links, cast(PhysicalBody, mb.virtualRoot()), htype=HINGE_TYPE.PIN, params=params
)
# finalize and verify the multibody
mb.ensureCurrent()
mb.resetData()
assert allFinalized()
return mb
Because we run multiple simulations, we write a method ahead of time to cleanup everything whenever the simulation ends. This requires us to delete local variables and discard our containers and scene.
def cleanup():
global integrator, sp_opts, bd1
del integrator, sp_opts, bd1
discard(sp)
gc.collect()
discard(mb)
discard(fc)
Run simulations for each model#
Below is the run loop for each simulation. It loops through each sim with an increasing number of links and collects the time it takes to complete.
# Number of links we will run at
n_links_list = [3, 5, 8, 10, 13, 16, 20, 25]
sim_types = ["SOA", "fullyAugmented"]
for sim in sim_types:
runtimes = []
deriv_calls = []
for n_links in n_links_list:
# initialization
fc = FrameContainer("root")
mb = createMbody(fc, n_links)
# Modify the initial multibody state. Here we will set the first pendulum to 0.5 radians.
bd1 = mb.getBody("link_0")
bd1.parentHinge().subhinge(0).setQ([0.5])
bd1.parentHinge().subhinge(0).setU([0.0])
# Switching to fully augmented model
if sim == "fullyAugmented":
mb.toFullyAugmentedModel()
# Set up state propagator and select integrator type: rk4 or cvode
sp = StatePropagator(mb, integrator_type=IntegratorType.RK4)
integrator = sp.getIntegrator()
sp_opts = sp.getOptions()
# add a gravitational model to the state propagator
ug = UniformGravity("grav_model", sp, mb)
ug.params.g = np.array([0, 0, -9.81])
del ug
# Initialize integrator state
t_init = np.timedelta64(0, "ns")
x_init = mb.dynamicsToState()
sp.setTime(t_init)
sp.setState(x_init)
# register the timed event
h = np.timedelta64(int(1e7), "ns")
t = TimedEvent("hop_size", h, lambda _: None, False)
t.period = h
sp.registerTimedEvent(t)
del t
# Keeping track of runtime when advancing simulation
start_time = time.time()
sp.advanceTo(2.0)
end_time = time.time()
run_time = end_time - start_time
runtimes.append(run_time)
derivs = sp.counters().derivs
deriv_calls.append(derivs)
# General output
print(f"Number of links: {n_links}")
print(f"Time to run: {run_time}, derivs={derivs}, simtype={sim}")
# Cleanup
cleanup()
if sim == "fullyAugmented":
runtimesFA = runtimes
else:
runtimesSOA = runtimes
Number of links: 3
Time to run: 0.5896553993225098, derivs=800, simtype=SOA
Number of links: 5
Time to run: 0.9507579803466797, derivs=800, simtype=SOA
Number of links: 8
Time to run: 1.4788484573364258, derivs=800, simtype=SOA
Number of links: 10
Time to run: 1.8719995021820068, derivs=800, simtype=SOA
Number of links: 13
Time to run: 2.416515588760376, derivs=800, simtype=SOA
Number of links: 16
Time to run: 3.036313533782959, derivs=800, simtype=SOA
Number of links: 20
Time to run: 3.672475814819336, derivs=800, simtype=SOA
Number of links: 25
Time to run: 4.5920729637146, derivs=800, simtype=SOA
Number of links: 3
Time to run: 3.931762456893921, derivs=800, simtype=fullyAugmented
Number of links: 5
Time to run: 7.254469156265259, derivs=800, simtype=fullyAugmented
Number of links: 8
Time to run: 14.218537330627441, derivs=800, simtype=fullyAugmented
Number of links: 10
Time to run: 20.672817707061768, derivs=800, simtype=fullyAugmented
Number of links: 13
Time to run: 32.69570302963257, derivs=800, simtype=fullyAugmented
Number of links: 16
Time to run: 48.51436686515808, derivs=800, simtype=fullyAugmented
Number of links: 20
Time to run: 77.32109498977661, derivs=800, simtype=fullyAugmented
Number of links: 25
Time to run: 127.00069570541382, derivs=800, simtype=fullyAugmented
Benchmark Simulation Runtimes#
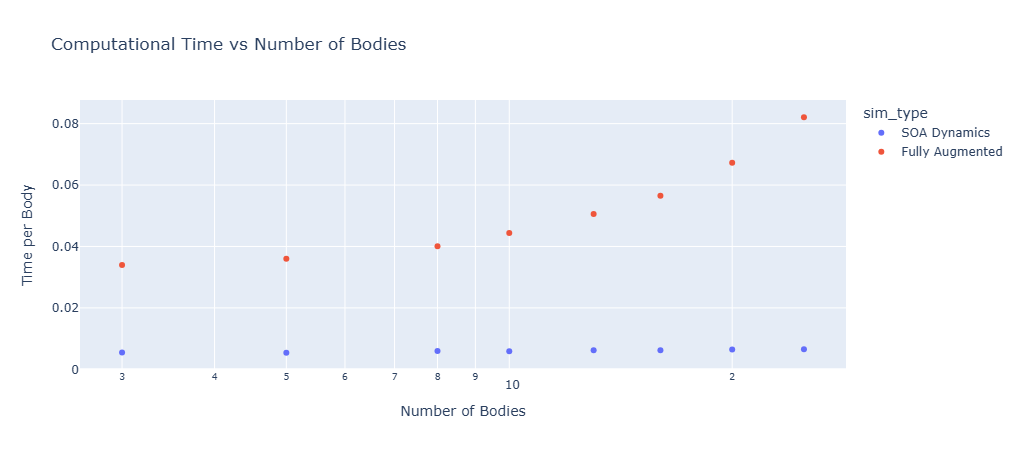
Below the benchmark results are plotted for normalized simulation run times with respect to the number of links. This is the time the simulation takes to run divided by the number of bodies. The Fully Augmented model is compared to kdlfex’s typical SOA Dynamics simulation.
runtimes = runtimesSOA
normalized_times = np.array(runtimes) / np.array(n_links_list)
normalized_times_FA = np.array(runtimesFA) / np.array(n_links_list)
run_data_SOA_df = pd.DataFrame(
{
"NLinks": n_links_list,
"RunTimes": runtimes,
"NormalizedTimes": normalized_times,
}
)
run_data_SOA_df["sim_type"] = "SOA Dynamics"
run_data_FA_df = pd.DataFrame(
{
"NLinks": n_links_list,
"RunTimes": runtimesFA,
"NormalizedTimes": normalized_times_FA,
}
)
run_data_FA_df["sim_type"] = "Fully Augmented"
run_data = pd.concat([run_data_SOA_df, run_data_FA_df], ignore_index=True)
# Create scatter plot
fig = px.scatter(
run_data,
x="NLinks",
y="NormalizedTimes",
color="sim_type",
title="Computational Time vs Number of Bodies",
labels={"NLinks": "Number of Bodies", "NormalizedTimes": "Time per Body"},
log_x=True,
)
# Show plot if not running in a test environment
if not os.getenv("DTEST_RUNNING", False):
fig.show()
Summary#
By running simulations using SOA Dynamics and Fully Augmented systems, you can see how Spatial Operator Algebra scales.
Further Readings#
Benchmark the n-link pendulum
Simulate collisions with a n-link pendulum